


{kind=link}
Set theory in DBMS explained simply means understanding how mathematical sets form the structure of relational databases. Set Theory defines how we group data, compare collections, and perform logical operations. Therefore, it becomes the mathematical foundation of DBMS set theory. Because databases manage structured collections of data, they rely heavily on set principles for consistency and performance.
The impact of set theory on database management systems is both theoretical and practical. It ensures logical data modeling, supports query optimization, and improves scalability. Moreover, it drives how SQL processes data efficiently. The role of set theory in DBMS design becomes clear when we analyze relational tables, keys, and constraints. In this article, you will learn how set theory applies to SQL databases, how relational algebra connects to it, and why it remains essential in modern database systems.
What Is Set Theory?
Set Theory is a branch of discrete mathematics that studies collections of objects called sets. Discrete mathematics set theory in DBMS provides the logical rules that structure relational databases. A set contains distinct elements, and each element belongs to that collection. Therefore, this idea directly applies to tables in databases.
A subset contains elements from a larger set. In SQL queries, filtered results act as subsets. Similarly, the universal set represents all records in a database table. Meanwhile, the empty set represents a query that returns no rows. These set theory basics for database students form the starting point for understanding database logic.
Fundamental Set Operations
Set theory operations in database systems include:
- Union
- Intersection
- Difference
- Cartesian Product
These operations directly translate into SQL commands. The union intersection difference in DBMS reflects SQL’s UNION, INTERSECT, and EXCEPT operators. Additionally, the Cartesian product forms the basis of JOIN operations. Therefore, the practical use of set theory in SQL appears every time a query runs.
Because of these principles, set theory concepts in relational databases shape how data is retrieved, filtered, and combined.
Foundations of Database Management Systems (DBMS)
A Database Management System (DBMS) is software that stores and retrieves structured data efficiently. It ensures security, integrity, and multi-user access. Popular relational database systems include:
- MySQL
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
These platforms implement relational models based on the mathematical foundation of DBMS set theory.
The Relational Model
The relational model was introduced by Edgar F. Codd. It organizes data into tables called relations. Rows represent tuples, and columns represent attributes. Because relations follow set properties, duplicate rows should not exist in theory. Moreover, the order of rows does not matter. Therefore, relational databases operate as sets of tuples.
This structure clearly demonstrates relational algebra and set theory in DBMS working together.
How Set Theory Forms the Backbone of Relational Databases
Tables as Mathematical Sets
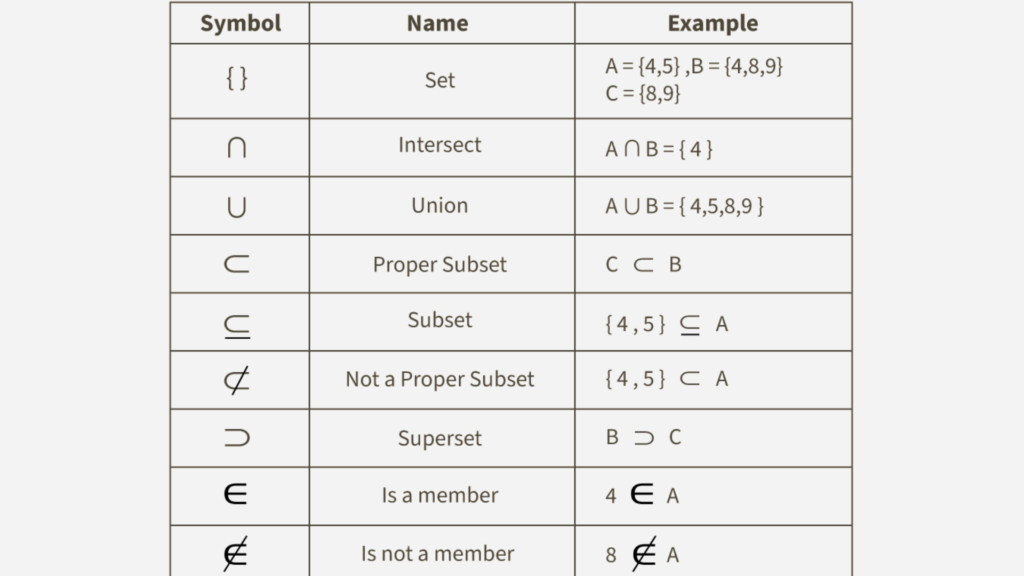
Tables behave like mathematical sets. First, they store unique rows. Second, they ignore order. Third, they group related attributes logically. Because of these characteristics, the importance of set theory in database design becomes obvious.
Primary keys enforce uniqueness. Constraints prevent duplication. Therefore, set rules protect data integrity and consistency.
SQL and Set Operations
How set theory applies to SQL databases becomes clear through set-based commands:
- UNION merges result sets.
- INTERSECT retrieves common rows.
- EXCEPT returns differences.
- SELECT creates subsets.
These set theory queries in relational database environments allow efficient data retrieval. Moreover, SQL processes complete sets rather than single records. As a result, the set based approach in database management improves performance and scalability.
Cartesian Product and Joins
The Cartesian Product pairs every row from one table with every row from another. Although SQL hides this complexity, JOIN operations rely on this principle. Therefore, real world applications of set theory in databases appear in customer-order joins, reporting queries, and analytics dashboards.
Relational Algebra and Set Theory
Relational algebra is a mathematical query language derived from Set Theory. It defines operations such as selection, projection, join, and rename. Because of this, relational algebra and set theory in DBMS remain deeply connected.
When comparing set theory vs relational algebra in DBMS, remember this: Set Theory provides the foundation, while relational algebra applies those rules to database relations. SQL then implements relational algebra practically. Therefore, SQL acts as the bridge between theory and application.
Practical Impact of Set Theory on DBMS
Query Optimization
Modern database engines use cost-based optimizers. They transform queries using algebraic rules. Therefore, set-based processing reduces execution time. Moreover, it improves indexing strategies and distributed query handling in cloud databases.
Data Integrity and Constraints
Primary keys, unique constraints, and foreign keys reflect set properties. They prevent duplicates and maintain relationships. Because of this, the impact of set theory on database management systems includes stronger data accuracy and reliability.
Database Normalization
Database normalization and set theory go hand in hand. Normalization organizes tables to remove redundancy. It separates data into logical subsets. Therefore, normalized databases avoid update anomalies and data inconsistencies.
Real-World Examples
Consider two tables: Online_Orders and Store_Orders. If you apply UNION, you merge both lists without duplicates. If you apply INTERSECT, you identify shared customers. These are practical set theory examples in database management.
In another scenario, a university database separates Students and Courses tables. By using foreign keys and joins, designers apply set principles. Therefore, the system remains scalable and logically structured.
These examples clearly show the role of set theory in DBMS design and its everyday application.
Advantages of a Set-Based Approach
The set based approach in database management offers several benefits:
- High efficiency
- Strong scalability
- Logical clarity
- Mathematical precision
Because SQL processes entire datasets at once, performance improves significantly. Moreover, cloud-native databases in 2026 continue to rely on set logic for distributed computing and analytics workloads.
Limitations and Considerations
Although relational theory assumes pure sets, SQL often uses multisets or “bags.” Therefore, duplicates may appear unless DISTINCT is specified. Additionally, performance depends on indexing and execution plans. However, despite these limitations, the mathematical foundation of DBMS set theory remains central to database architecture.
Conclusion
Set Theory provides the core structure behind relational databases. It defines how tables store data, how queries retrieve results, and how joins combine relations. Therefore, the impact of set theory on database management systems is foundational and ongoing.
Understanding set theory basics for database students improves SQL skills, database design knowledge, and query optimization techniques. Moreover, recognizing the practical use of set theory in SQL strengthens both academic learning and real-world implementation. As data systems evolve with AI-driven analytics and cloud platforms, set theory continues to power relational databases with precision and reliability.
I never realized how deeply set theory influences relational databases until I read this post. The way you explained unions, intersections, and Cartesian products made it all click!
This blog on Set Theory and its impact on Database Management Systems is extremely well-written and insightful. I really like how you explained the core principles of set theory in a way that even someone without a deep mathematical background can understand. The connection you made between sets, relations, and how databases use these concepts to organize and retrieve information was both clear and practical. I especially appreciated the examples that showed how operations like union, intersection, and Cartesian product form the foundation of modern relational databases — it made the theory come alive. The article flows smoothly, avoids unnecessary jargon, and provides real educational value for students as well as professionals. I must say I like this blog very much, and I will certainly keep coming back to learn more from posts like this.