


{kind=link}
Every time you write code and run it through a compiler, a remarkable sequence of processes transforms your human-readable source code into machine-executable instructions. At the very foundation of this transformation sits a mathematical concept called finite automata. Understanding finite automata and their role in compiler design unlocks a deeper appreciation of how programming languages work, why compilers catch certain errors at specific stages, and how language designers build the tools developers rely on every day.
What Are Finite Automata?
A finite automaton is a mathematical model of computation that reads an input string one symbol at a time and decides whether the string belongs to a particular language. It operates by moving through a finite set of states based on the current input symbol and a defined transition function.
Every finite automaton consists of five components. The first is a finite set of states representing every possible condition the machine can occupy. The second is an input alphabet — the set of symbols the automaton recognizes. The third is a transition function that defines which state the automaton moves to for each input symbol from each current state. The fourth is a designated start state where processing begins. The fifth is a set of accepting states — if the automaton finishes reading the input while in an accepting state, it accepts the string as valid.
Regular Languages and Their Importance
Finite automata recognize exactly the class of languages called regular languages. A regular language is any language that a finite automaton can accept. Regular languages play a foundational role in compiler design because the tokens — the basic building blocks of programming language syntax — all belong to this category.
Identifiers, keywords, integer literals, floating-point numbers, string literals, operators, and punctuation symbols all follow patterns that regular expressions describe and finite automata recognize. This correspondence between regular languages, regular expressions, and finite automata creates the theoretical foundation for lexical analysis — the first and most fundamental phase of compilation.
The Lexical Analysis Phase
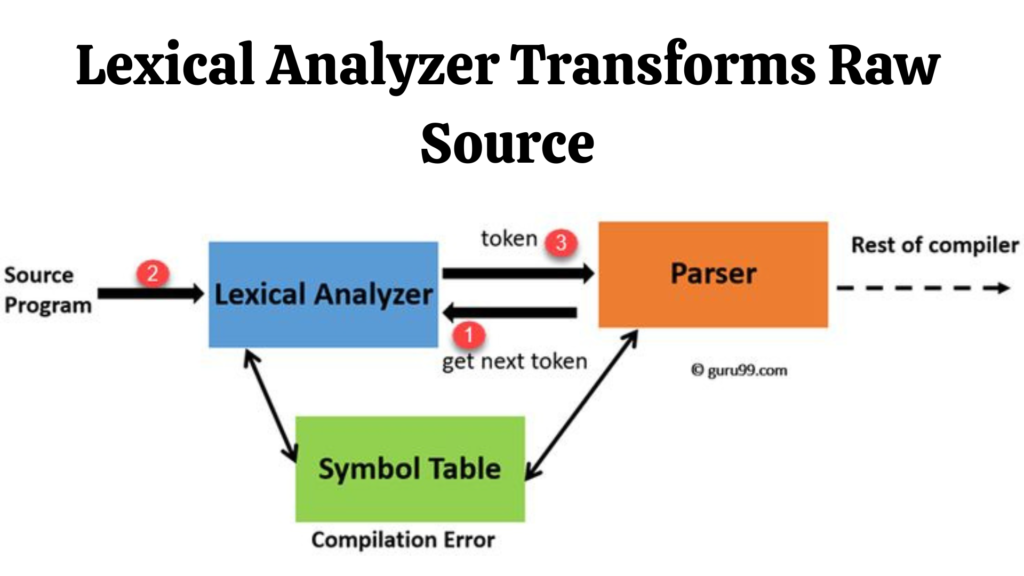
Lexical analysis is the first phase of a compiler. The lexical analyzer — also called a lexer or scanner — reads the raw source code character by character and groups characters into meaningful units called tokens. Every token represents a single logical unit of the programming language — a keyword like while or if, an identifier like variableName, an operator like plus or equals, or a literal value like 42 or 3.14.
For example, when the lexer encounters the character sequence i-f followed by whitespace in a C program, the DFA transitions through states that recognize this sequence as the keyword if rather than an identifier beginning with those letters. The distinction matters because the compiler handles keywords and identifiers differently in subsequent phases.
From Regular Expressions to Finite Automata
Compiler designers specify token patterns using regular expressions because regular expressions provide a concise, human-readable notation for describing the patterns that tokens follow. The compiler construction pipeline then automatically converts these regular expressions into finite automata that the generated lexer executes at runtime.
The second algorithm — subset construction — converts the NFA into an equivalent DFA. The DFA is more efficient for implementation because it makes exactly one transition per input symbol, eliminating the ambiguity and backtracking that NFA execution would otherwise require. Compiler construction tools like Lex and Flex automate both conversion steps, generating optimized DFA-based lexers from regular expression specifications that compiler designers provide.
DFA Minimization for Efficiency
A DFA generated directly from an NFA through subset construction often contains more states than necessary. Redundant states increase memory consumption and slow down the lexer’s scanning speed — factors that matter when lexers process large source files with millions of characters.
DFA minimization algorithms identify and merge equivalent states — states that behave identically for all possible input sequences — producing the smallest possible DFA that still recognizes the same language. Compiler construction tools apply minimization automatically, ensuring that generated lexers operate at maximum efficiency without requiring manual optimization from the compiler designer.
Finite Automata Beyond Lexical Analysis
Error recovery in the lexer uses finite automata principles to identify the point where the input deviates from any valid token pattern and recover gracefully — reporting a meaningful error message and resuming scanning rather than crashing on the first unrecognized character.
Symbol table management benefits from the efficient string pattern matching that DFA-based structures enable. Compilers use finite automaton principles when implementing keyword recognition tables that distinguish reserved words from user-defined identifiers with minimal comparison overhead.
Tools That Use Finite Automata in Compiler Construction
Lex and Flex generate C-based lexical analyzers from regular expression specifications. The developer writes token patterns as regular expressions, and Flex converts them into an optimized DFA-based scanner automatically. GCC, Clang, and virtually every production-quality compiler use this approach or an equivalent internal implementation.
ANTLR — Another Tool for Language Recognition — generates lexers and parsers from combined grammar specifications. Its lexer component implements DFA-based token recognition that handles complex language specifications including Unicode input, multiline string literals, and nested comment structures that simpler regular expression engines struggle with.
Why Computer Science Students Must Understand Finite Automata
Every computer science student who works with programming languages, builds language tools, or designs software systems benefits from understanding finite automata deeply. The concepts apply far beyond compiler design.
Text editors use finite automata for syntax highlighting — the DFA-based pattern matching that colors keywords, strings, and operators differently processes each keystroke in real time. Search engines use finite automata principles for efficient pattern matching across enormous text corpora. Network intrusion detection systems use finite automata to match network packet payloads against known attack signatures at line speed. DNA sequence analysis tools use finite automata to identify patterns in genomic data with the same theoretical foundations that compiler lexers use to identify tokens in source code.
Conclusion
Finite automata form the mathematical backbone of lexical analysis and play a foundational role throughout the compiler design process. They provide the theoretical framework that transforms informal token descriptions into precise, implementable, and efficiently executable pattern recognizers that every compiler depends on. From Thompson’s construction through subset construction, DFA minimization, and lexer generation, finite automata connect formal language theory directly to the practical tools that power modern software development.
I found your article on Finite Automata and Their Role in Compiler Design absolutely fascinating. The way you explained how automata theory underpins lexical analysis and parsing made the connection between abstract mathematics and practical programming very clear. I especially appreciated the step-by-step examples showing how finite automata help in token recognition—it really brought the concept to life. Your post manages to simplify a highly technical subject without losing depth, which is no easy task. Brilliant work, Jazz Cyber Shield! This is definitely a must-read for computer science students and enthusiasts alike.
Your explanation of finite automata in compiler design was spot on. I appreciated how you linked theory with practical implementation, especially the part about lexical analysis. It made a complex topic much easier to grasp.
As a computer science student, this article helped me finally grasp how finite automata form the backbone of lexical analysis in compilers. It clearly explains DFA vs NFA and their real-world relevance in parsing source code. A must-read for anyone diving into compiler theory!